
How to Train LLM on your own Data (4 Methods)

Mike Huddlesman
Meet Mike Huddlesman, the brilliant mind behind CopyRocket AI

Getting started with training a large language model (LLM) on your own data can seem like a daunting task, especially if you’re aiming to customize it for specific needs such as powering a custom chatbot.
But, what if you could leverage your existing content, like your website or PDFs, to create a private LLM that understands your domain thoroughly?
This guide will introduce you to the process of using CopyRocket AI’s custom chatbot training capabilities to do just that. Whether you’re looking to fine-tune a pre-trained model, enhance customer interactions, or develop a domain-specific LLM, the integration of proprietary data through smart data ingestion, model training, and fine-tuning techniques will be crucial.
We’ll cover everything from the basics of natural language processing and machine learning to more advanced concepts like model architecture, dataset preparation, and the training process.
By demystifying data science and artificial intelligence aspects, specifically deep learning and neural networks, you’ll gain insights into optimizing your AI model for enhanced performance when tackling a specific task.
This hands-on approach not only augments the capabilities of existing models through transfer learning but also prepares you for successful prompt engineering and retrieval augmented generation.
Whether your goal is to expand an open-source LLM or create a custom model that excels at understanding and generating natural language, this guide is your starting point to mastering the art of training LLMs with your data.
Checkout our Free AI Tool;
- Free AI Image Generator
- Free AI Text Generator
- Free AI Chat Bot
- 10,000+ ChatGPT, Cluade, Meta AI, Gemini Prompts
Also Learn, How to run LLM locally (100% Working)
Why Training Your LLM Is hard For Non-Techies?
Complexity of Natural Language Processing (NLP)
The intricacies of natural language processing (NLP) make training a large language model (LLM) challenging for those without a background in data science or artificial intelligence. NLP involves understanding and generating human language in a way that is natural and effective. This includes:
- Parsing and understanding diverse grammatical structures
- Deciphering context and implied meanings
- Recognizing and generating slang and idioms
Abundance of Data Necessary
The success of LLM training heavily depends on having access to vast amounts of training data. This data should be:
- High-quality and relevant to the specific task
- Varied enough to cover the breadth of the domain
- Appropriately labeled and organized for effective learning
Advanced Technical Requirements
Developing a custom LLM involves navigating complex model architecture and engaging in extensive data preparation processes that require specialized knowledge in:
- Machine learning and deep learning principles
- Effective model training and fine-tuning techniques
- Understanding of neural networks and how they process information
Ongoing Maintenance and Fine-tuning
After the initial training, a private LLM requires continuous monitoring and adjustments to maintain optimal performance. This includes:
- Regular updates with new training data to keep the model current
- Adjustments based on feedback and changing user needs
- Evaluating model performance and making necessary tweaks
Training an LLM on your own data like powering a custom chatbot or creating a domain-specific LLM provides valuable benefits but comes with its set of challenges, particularly for non-technical individuals. By understanding these hurdles—from the complexities of NLP and data collection requirements to the technical know-how needed for model training and ongoing maintenance—you can better prepare for the task ahead.
How to Train LLM On Your Data
#1 Using Your Website
To get started with training your large language model (LLM) on your own data, leveraging the content from your website, follow this step-by-step tutorial. This process will guide you through creating a custom LLM that can significantly enhance your customer interactions by understanding your domain’s specific needs.
Sign Up for Free Account: Begin by navigating to app.copyrocket.ai and signing up for a free account. Upon registration, you’ll receive 1000 credits for free, getting you started on your LLM training without any initial investment.
Navigate to Chatbot Training Settings: From your dashboard, go to “chat settings” and select “chatbot training.” This area is where you’ll initiate the training process for your custom LLM.
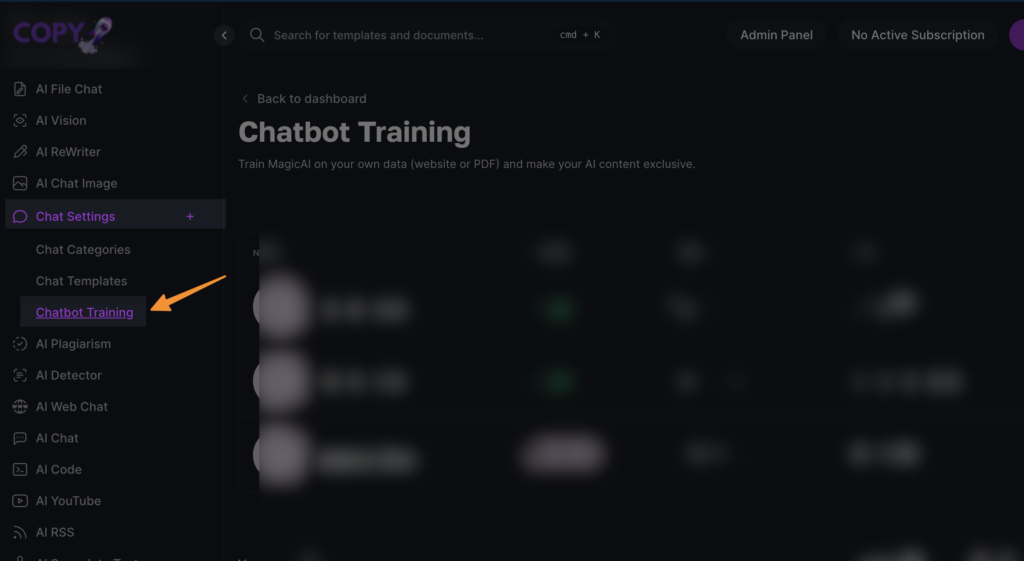
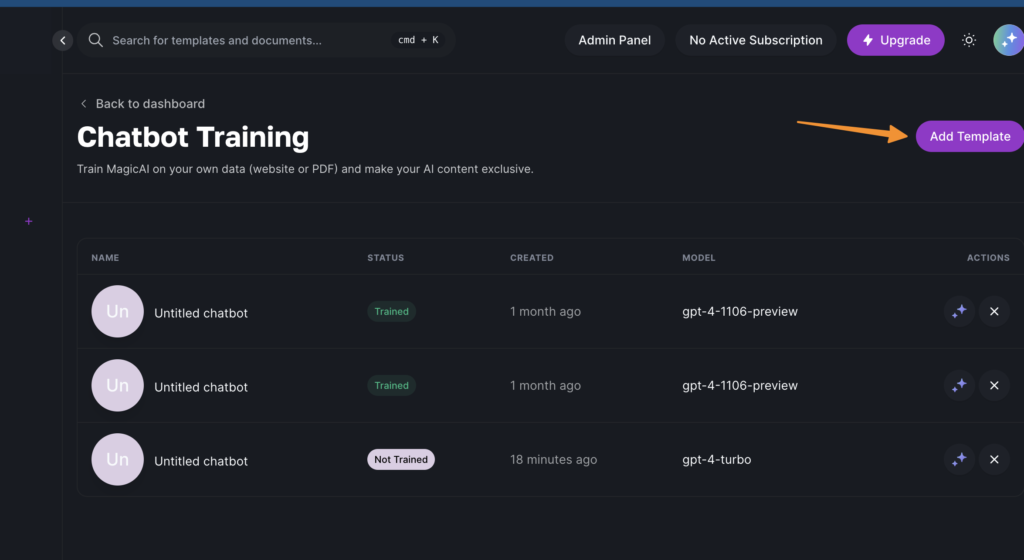
Adding a Template: Click on the “add template” button. This step is crucial as it prepares your setup for importing data from your website.
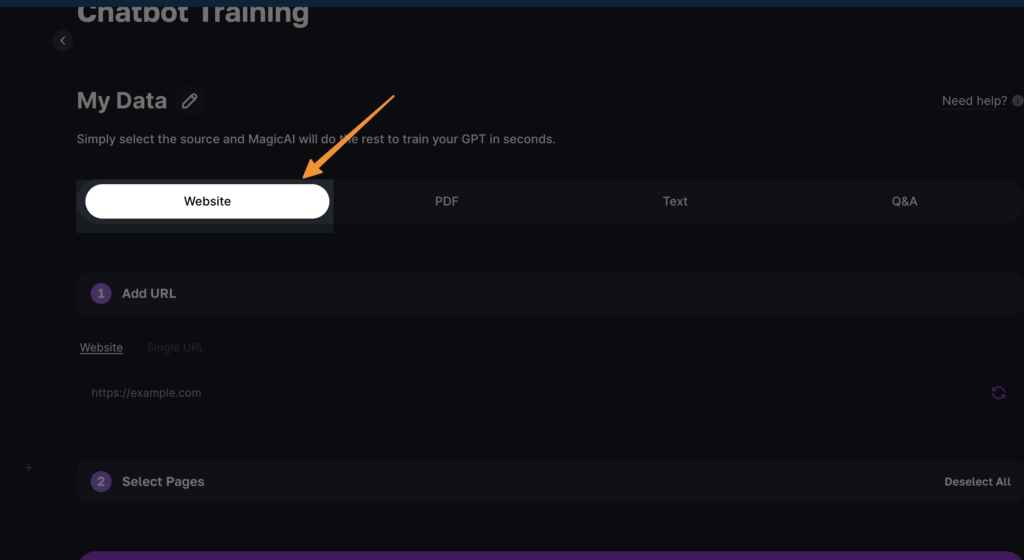
Select Website Data Ingestion Method: You will see four methods for data ingestion. Since we’re focusing on website content, click on “website” (note: this is for multiple pages, not a single page) and then click the reload button next to it. This action instructs the system to start scraping your website pages for training data.
Disable Cloud Flare if Necessary: If your website uses Cloud Flare, make sure to disable it temporarily. This ensures that the scraping process goes smoothly without any interruptions or blockages.
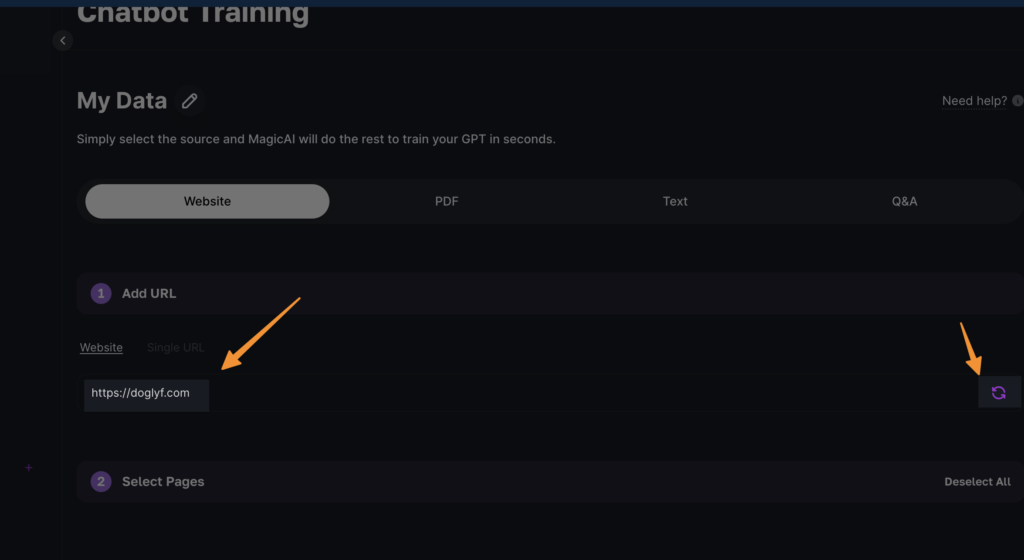
Select URLs for Training: Once the system has scraped your website, review and select all URLs you wish to include in the training process. Be selective to ensure the data is relevant to the LLM’s intended task.
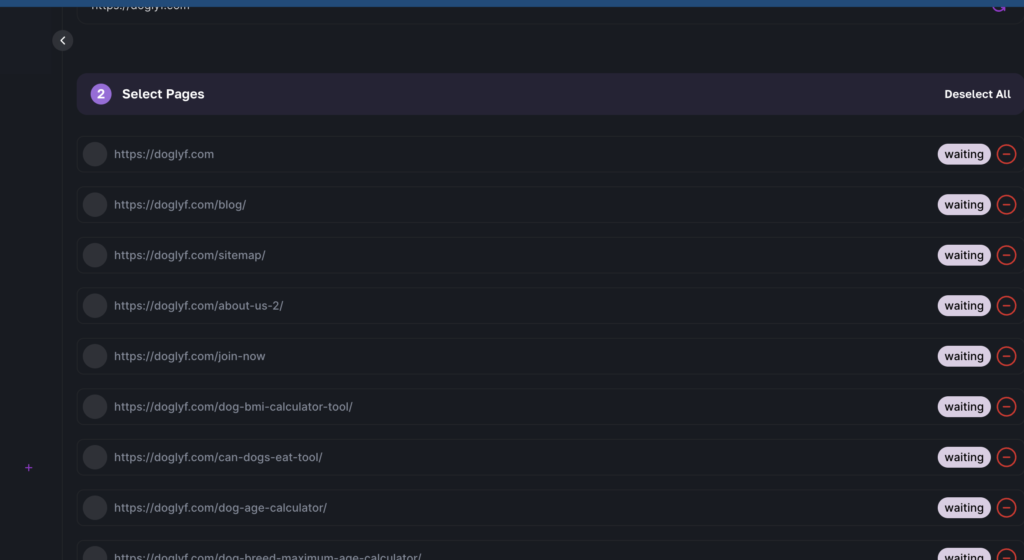
Initiate LLM Training: After selecting the necessary URLs, click on the “train GPT button.” This begins the process of training your custom LLM with the data obtained from your website. The system’s algorithms will start learning from your content, adapting the AI model to better serve your specific domain and task.
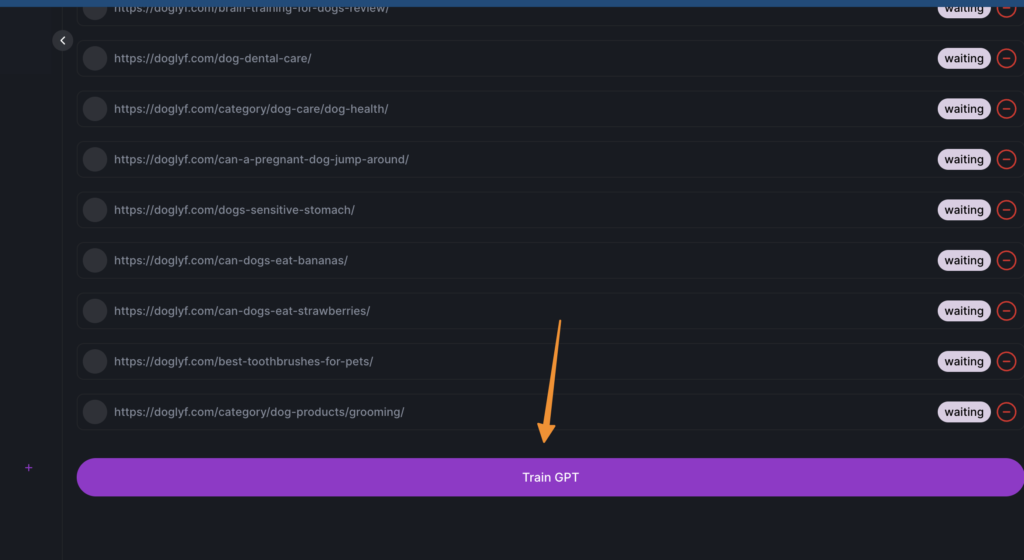
By following these steps, you’ll be well on your way to developing a private LLM tailored to your unique requirements, whether it’s enhancing customer interactions, facilitating prompt engineering, or achieving superior model performance through fine-tuning and transfer learning.
Remember, the quality of your training data and the specifics of your data preparation process play a critical role in the success of your custom LLM, ensuring it delivers accurate and relevant outcomes for your domain-specific tasks.
#2 Using PDF Documents for LLM Training
Leveraging PDF documents for training your custom large language model (LLM) can significantly enhance the model’s knowledge and understanding, especially when your data resides in proprietary documents or published resources. Here’s how to incorporate PDF documents into your LLM training strategy with [app.copyrocket.ai](https://app.copyrocket.ai).
Sign Up for a Free Account: Start by visiting app.copyrocket.ai and create a free account. This step will grant you 1000 credits, allowing you to begin the training process without any financial commitment.
Access Chatbot Training Settings: From the main dashboard, locate and enter the “chat settings” section, then click on “chatbot training”. This is where the magic begins.
Add a Template: Hit the “add template” button to set your training environment. This is essential for preparing your account for PDF data ingestion.
Select PDF as Your Data Ingestion Method: Among the four available data ingestion methods, choose “PDF” for uploading document-based data. This option is tailored for processing and extracting text from your PDF files.
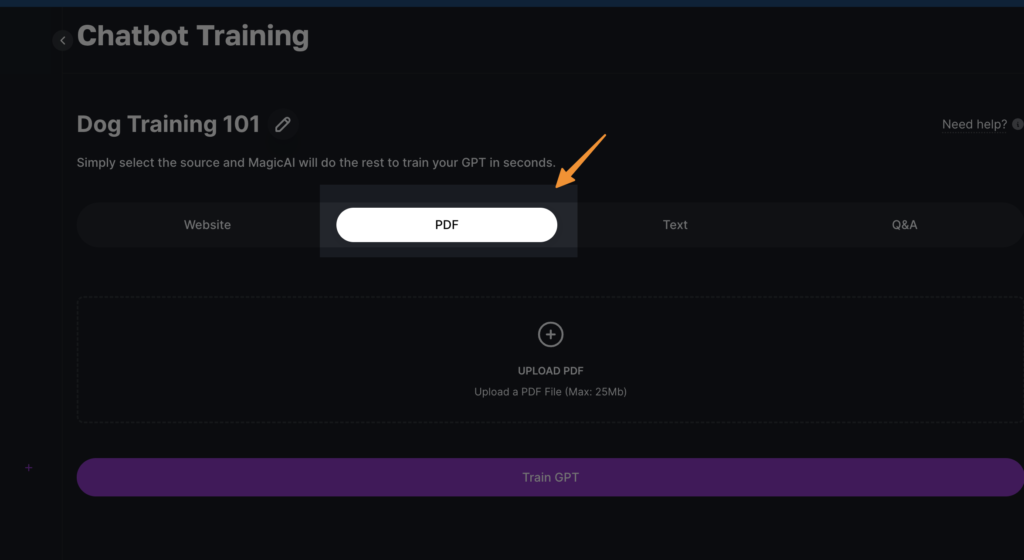
Upload Your PDF File: Navigate through your files and select the PDF document you wish to use for training your LLM. You can upload multiple documents if necessary to cover a broader scope of information.
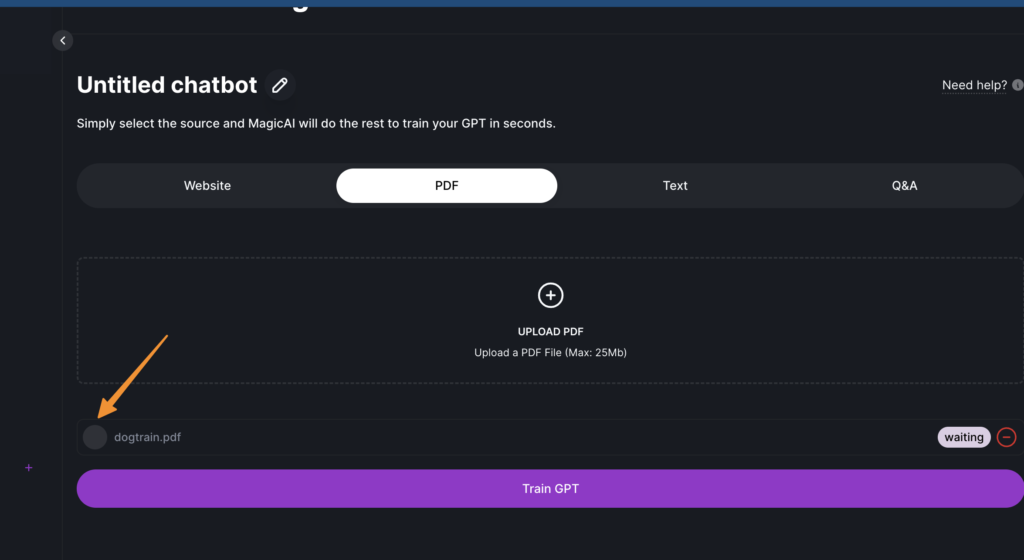
Initiate the Training Process: With your PDF file(s) uploaded, click on the “train GPT button”. This will start training your custom LLM using the text extracted from the PDF documents. The system employs advanced machine learning and natural language processing techniques to learn from the data provided in your PDFs.
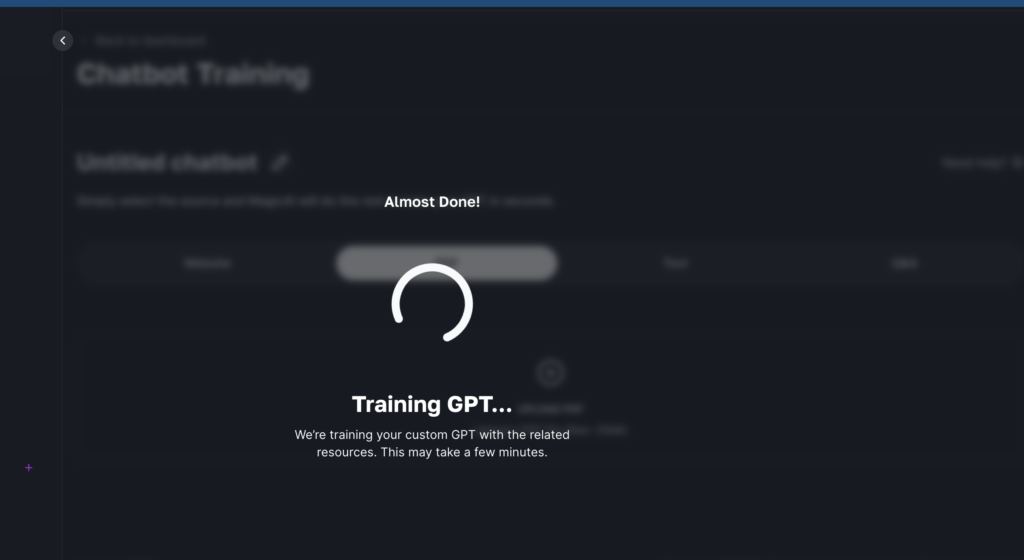
By adopting this approach, you’re not just broadening the knowledge base of your AI model but also tailoring it to understand and generate content that aligns closely with your domain-specific needs.
Training LLMs using proprietary PDF documents ensures your private LLM, custom model, or even pre-trained LLM gains proficiency in your specific task, improving overall model performance.
Whether it’s for enhancing customer interactions, conducting in-depth data science research, or achieving breakthroughs in artificial intelligence, the right training data, coupled with effective data preparation and model training techniques, is key to unlocking the potential of generative AI models.
#3 Train LLM Using Text
Training your large language model (LLM) using text is a straightforward process, particularly beneficial for honing your model’s abilities in natural language processing and enhancing its performance on specific tasks. Here’s a step-by-step guide to get you started:
Sign Up for a Free Account: Initially, visit app.copyrocket.ai to create your free account. This step provides you with 1000 credits to kickstart your LLM training without any cost.
Access Chatbot Training Settings: Navigate through your dashboard to find the “chat settings”, then proceed to “chatbot training”. This section is prepared for your model training adventure.
Add a Template for Training: Click on the “add template” button. This action is essential for setting up your environment for training llms with text data.
Selecting Data Ingestion Method: Among the available options, choose the “Text” tab for text-based training. This method is designed for deep learning models to learn from textual data effectively.
Paste Your Training Data: In the provided text window, you can paste up to 160k tokens of your training data. This allows for a comprehensive training data set, ensuring your ai model learns from a rich dataset aligned with your specific needs.
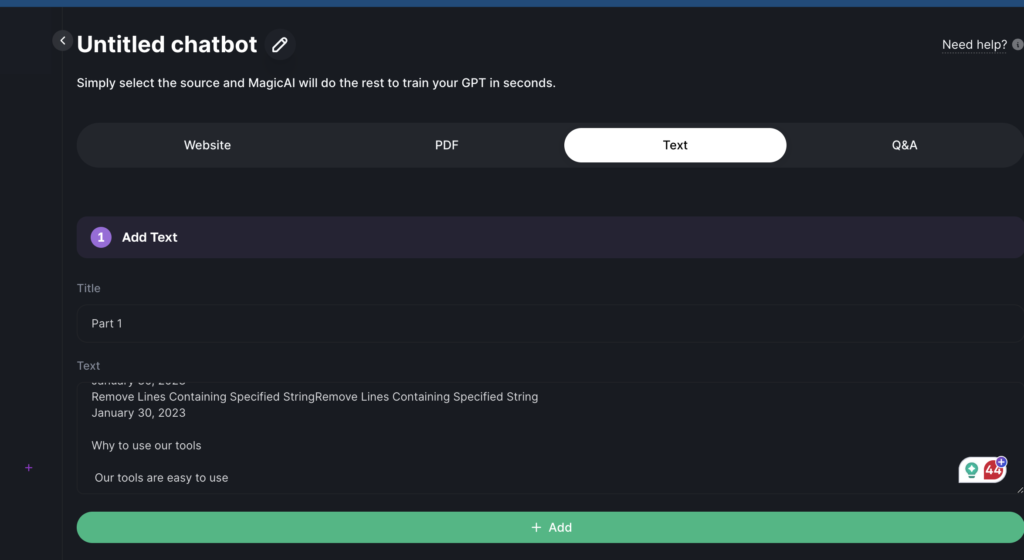
Initiate LLM Training: With your data ready, click the “train GPT button”. This final step starts the process using advanced machine learning techniques to train your custom LLM, focusing on the nuances of your proprietary data or specific task requirements.
By incorporating comprehensive training datasets, rigorous data preparation, and leveraging the capabilities of neural networks, this method facilitates the fine-tuning of your custom llm or even augmenting pre trained models for superior model performance.
Whether you are working towards improving customer interactions, engaging in data science projects, or developing domain specific solutions, the right approach to training llms can set the foundation for breakthroughs in artificial intelligence.
Training your model using text data not only enriches its understanding of natural language but also paves the way for innovations in generative ai, prompt engineering, and more advanced applications like retrieval augmented generation within the artificial intelligence spectrum.
#4 Using Questions and Answers
Training your large language model (LLM) through a Questions and Answers mechanism is a direct method for enhancing its ability to manage conversational tasks, comprehend content contextually, and generate accurate responses. Here’s how you can set this up with ease on:
Sign Up for a Free Account: Jumpstart by signing up at app.copyrocket.ai to receive 1000 free credits, giving you a head start on training without any upfront cost.
Access Chatbot Training Settings: From your dashboard, go directly to “chat settings” followed by “chatbot training” to set the stage for your LLM’s learning path.
Add a Template: Click on the “add template” button, a crucial step for configuring your training setup tailored to Q&A-based learning.
Select the “Q&A” Method: Choose the “Q&A” tab from among the four data ingestion methods available, specifically designed for Q&A-driven training scenarios.
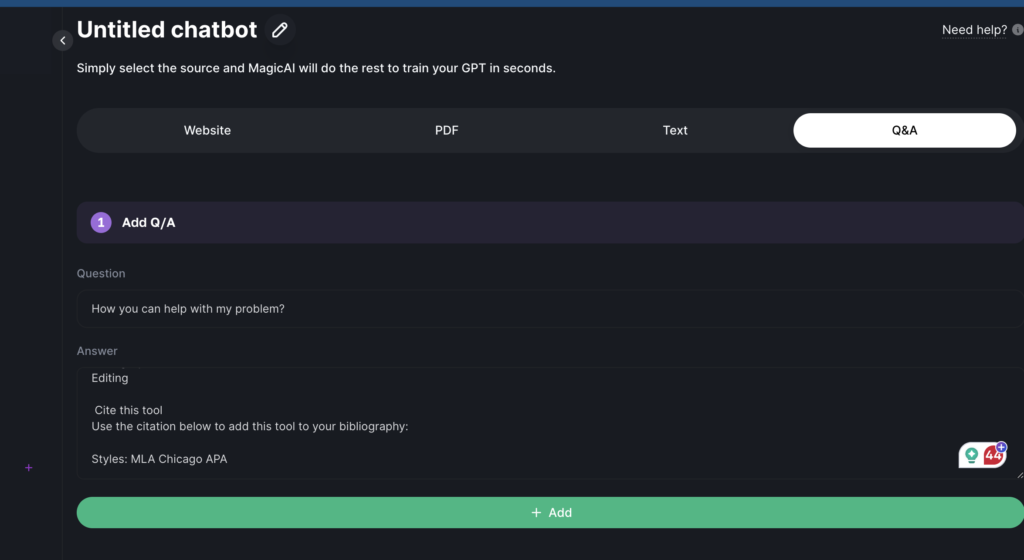
Input Your Questions and Answers: This step allows you to feed your GPT LLM with a series of questions and corresponding answers, pivotal for custom training on how to accurately understand and respond to queries.
Initiate the Training Process: Once your Q&A data is in place, proceed by clicking the “train GPT button”, initiating the tailored training of your LLM based on your specific questions and answers.
Implementing this training approach not only enhances the model’s proficiency in Q&A but also significantly improves its overall performance in natural language processing, making it adept at handling domain-specific tasks, customer interactions, and even engaging in complex data science inquiries.
With a focus on leveraging the advancements in neural networks, machine learning, and AI models’ training capabilities, this method embodies the essence of artificial intelligence by fostering a deeper understanding of conversational contexts and yielding more precise responses.
Frequently Asked Questions
Can I train a large language model (LLM) on my own proprietary data?
Yes, you can train an LLM on your own data. By using platforms like CopyRocket.ai, you can input your proprietary data for training, thereby customizing the model to better suit your specific needs and tasks. This process enhances the model’s understanding of your unique datasets and can improve overall model performance in tasks related to your domain.
How does training data affect the performance of a custom LLM?
The quality and relevance of training data are crucial for the success of a custom LLM. High-quality training data ensures that the AI model learns the nuances of the language and tasks it will perform.
Effective data preparation and training enable the model to achieve better accuracy in natural language processing, understand specific tasks more deeply, and perform domain-specific functions with higher precision.
What is the advantage of using questions and answers for LLM training?
Using a questions and answers format for training LLMs directly improves their ability to manage conversational tasks, comprehend queries in context, and generate accurate, relevant responses.
This method is particularly useful for enhancing customer interactions, conducting refined data science inquiries, and achieving superior performance in generative AI applications focused on natural language understanding and response generation.
Conclusion
In conclusion, the evolution and training of large language models (LLMs) represent a remarkable leap forward in the field of artificial intelligence, opening up new avenues for data science, natural language processing, and generative AI. The methods and processes discussed offer a comprehensive guide for anyone looking to harness the power of LLMs, highlighting the importance of proper data preparation, model training, and the strategic choice of training data.
Whether you’re engaging in fine-tuning a custom LLM, leveraging pre-trained models, or exploring the realms of private LLMs and domain-specific models, the underlying principle remains the same: the quality of your training process and the relevance of your dataset directly influence your model’s performance.
By adopting data ingestion practices tailored to your specific needs, focusing on neural networks, and applying techniques such as retrieval augmented generation and prompt engineering, you can significantly enhance the capabilities of your AI models. This tailored approach not only improves customer interactions but also paves the way for innovations in transfer learning, open-source LLMs, and the development of custom models designed to address the unique challenges and tasks of your domain.
The landscape of AI is constantly evolving, with deep learning and machine learning leading the charge. For those looking to advance in this dynamic field, understanding the architecture and training of LLMs is crucial. Remember, the journey of training an LLM on your own data, whether starting with a base model or an existing model, is both a challenge and an opportunity to redefine what is possible within the artificial intelligence spectrum.
Frequently Asked Questions
Written by
Mike Huddlesman
Meet Mike Huddlesman, the brilliant mind behind CopyRocket AI. As the founder of this innovative company, Mike brings a wealth of experience in machine learning, PHP, and Next JS to the table. With h
View all postsYour AI Marketing Agents
Are Ready to Work
Stop spending hours on copywriting. Let AI craft high-converting ads, emails, blog posts & social media content in seconds.
Start Creating for FreeNo credit card required. 50+ AI tools included.
Related Articles
 General
GeneralNotebookLM For Coders: Turn Docs Into Faster Code
Code work often fails for a simple reason. You do not have the right context at the right time. You read docs in one tab, skim tickets in another tab, and then...

 General
GeneralHow to Optimize for AI Search in 2026: The Complete Guide
AI search has shifted from experimental feature to primary search method for millions of users. ChatGPT Search, Google AI Overviews, Perplexity, Claude, and Gem...
 General
GeneralClaude Opus 4.6 Review: Here's What New!
Claude Opus 4.6 from Anthropic draws attention because teams want an AI model that writes better code, follows instructions, and stays consistent across long se...