Claude Opus 4.7 Review: I Tested 5 Apps in One Go (Full Results)
Raman Singh
Raman Singh is a highly skilled marketing professional who serves as the head of marketing at Copyrocket AI

Anthropic shipped Claude Opus 4.7 on April 16, 2026, and I put it through a real test the same day — five different applications, one-shot prompts, no iteration. The results surprised me.
This review breaks down what the new Opus model actually delivered: a full-stack job tracker, a UI/UX landing page, a Python CLI tool using the Anthropic SDK, an Electron Mac app, and a coding duel game.
Here is what worked, what slipped, and why this release matters if you build with AI.
Key Takeaways
Claude Opus 4.7 scores 87.6% on SWE-bench Verified and 64.3% on SWE-bench Pro, up from 80.8% and 53.4% on Opus 4.6 — the biggest jump on hard coding benchmarks this year.
The new xhigh effort level sits between high and max, and Claude Code now defaults to xhigh for all plans, giving you deeper reasoning without max-mode latency.
Vision resolution jumped to 2,576 pixels on the long edge — over 3x the prior Claude limit — which makes dense screenshots, diagrams, and UI mockups far more readable to the model.
Opus 4.7 kept the same price as Opus 4.6: $5 per million input tokens and $25 per million output tokens, including across Amazon Bedrock, Vertex AI, and Microsoft Foundry.
Across my five one-shot app tests, Opus 4.7 scored 5/5 on four builds and 4.5/5 on one. None broke. None needed iteration.
The new
/ultrareviewcommand in Claude Code runs a senior-reviewer-style pass on your changes and flags design and logic gaps that normal reviews miss.
What Is Claude Opus 4.7 and Why It Matters
Claude Opus 4.7 is Anthropic's most capable generally available model as of April 2026. The model ID is claude-opus-4-7 and it is a direct successor to Opus 4.6, which launched February 5, 2026. You can access it in Claude.ai, Claude Code, the Anthropic API, Amazon Bedrock, Google Vertex AI, and Microsoft Foundry. The full announcement sits on Anthropic's site at anthropic.com/news/claude-opus-4-7.
Anthropic's framing is that Opus 4.7 handles long-horizon, multi-step work with more rigor, follows instructions more literally, and verifies its own outputs before reporting back. In plain English: fewer "I've implemented the change" replies that turn out to be wrong at review time.
There is also a bigger model sitting above it. Claude Mythos Preview — a more powerful system — remains restricted to a small group of cybersecurity partners under Anthropic's Project Glasswing initiative. For everyone else, Opus 4.7 is the top of the stack.
Try Opus 4.7 On Our Free AI Chat Bot here.
The Benchmark Numbers You Should Care About
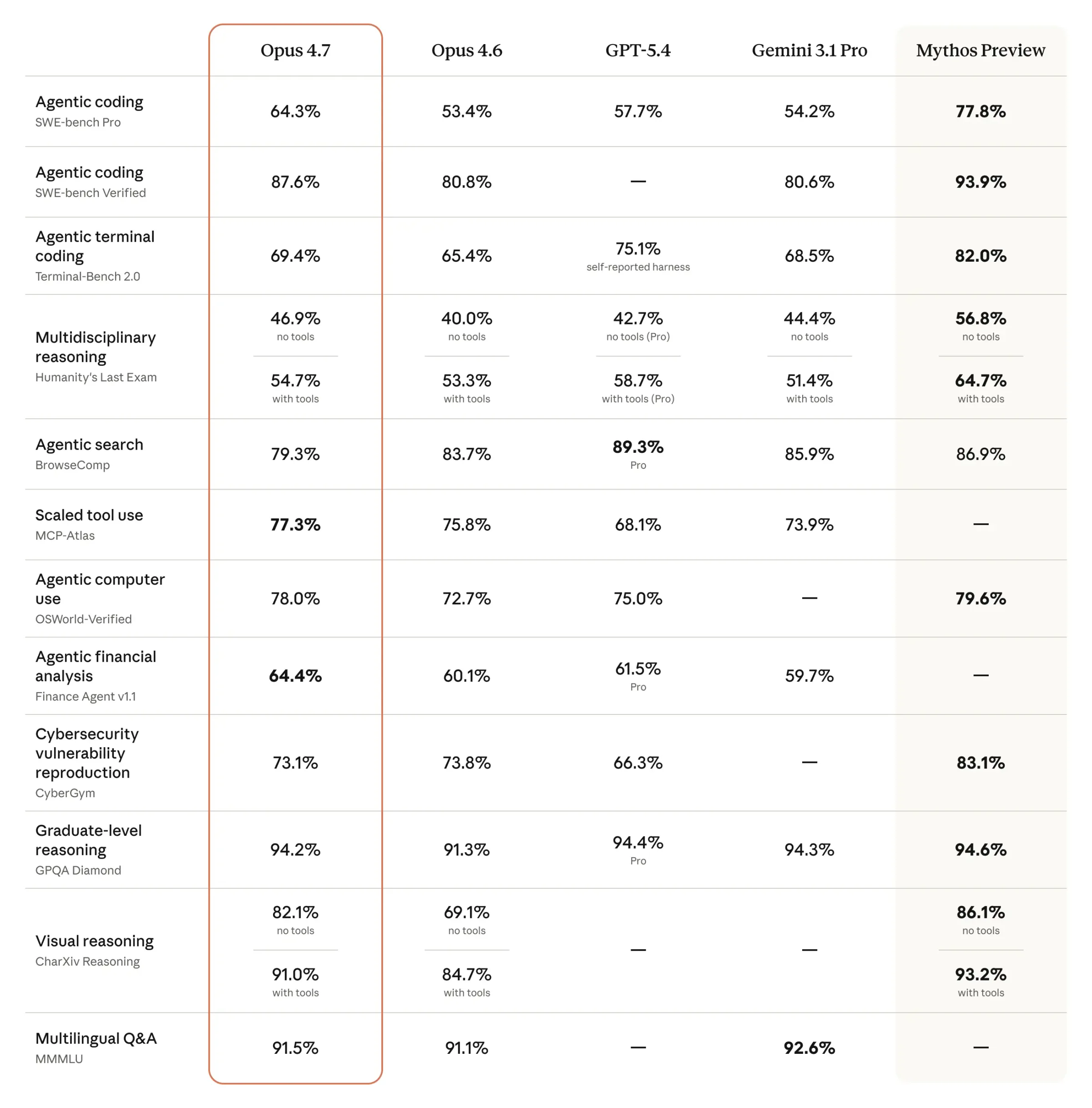
The headline gains are concentrated on coding and agentic reasoning:
SWE-bench Verified: 87.6% (up from 80.8% on Opus 4.6)
SWE-bench Pro: 64.3% (up from 53.4%) — beats GPT-5.4's 57.7%
CursorBench: 70% (up from 58%)
Terminal-Bench 2.0: 69.4% (up from 65.4%)
OSWorld-Verified (computer use): 78.0% — ahead of GPT-5.4 at 75.0%
GPQA Diamond (reasoning): 94.2% — the top three frontier models are now within a point of each other
The 10.9-point jump on SWE-bench Pro is the signal that matters. SWE-bench Pro tests harder, less-contaminated problems across four programming languages, and a double-digit improvement there means the gains are real, not benchmark theater.
One weak spot worth flagging: BrowseComp dropped from 83.7% on Opus 4.6 to 79.3% on Opus 4.7, while GPT-5.4 Pro holds 89.3%. If your agent does heavy web research, test both models before switching.
The Test Setup: Five Apps, One Prompt Each
I built each application in a single shot using Claude Code at the default xhigh effort. No brainstorming passes. No back-and-forth. One detailed prompt, one deliverable. The goal was to stress-test instruction following and single-turn production quality.
All five prompts are in the doc file here, Here is what happened.
App 1: Full-Stack Job Tracker — 5/5
The first test was a full-stack web app: a single-user job tracker with sign-up, login, a dashboard, an application list, filters, and analytics. I wrote a detailed prompt covering the backend, frontend, schema, and the landing page. I also asked for demo login credentials so I could test the auth flow fast.
Opus 4.7 delivered the whole stack in one go. The landing page was a clean one-section hero with a get-started button that routed to signup. The login page had the demo credentials pre-filled. Once inside, the dashboard showed total applications, seeded status counts (saved, applied, interview, offer), and a weekly chart.
I tested every feature I could think of:
Filters for remote jobs, source (LinkedIn, referrals), and date ranges — all working.
Add application form with company, title, URL, salary range, remote toggle, source, and notes — saved correctly.
Cover letter generator that took a job description and produced a cover letter for copy-paste.
Delete account flow — destructive, confirmed, and clean.
Zero visible bugs. Zero hallucinated UI. The app behaved like something a junior dev would ship after a week.
App 2: Focus Frame Landing Page (UI/UX) — 5/5
This was the favorite test. Focus Frame is a fictional deep-work scheduling app, and I asked Opus 4.7 to build a full marketing landing page as a single HTML file — no separate CSS, no multiple JS files. The prompt specified typography, color palette, animations, dark and light modes, SVG illustrations, a 3D mockup, hover states, navigation, testimonials, pricing, FAQ, and a newsletter.
Single file. One prompt. Done.
The output was striking. The hover states felt deliberate. The 3D mockup was auto-generated by the model. The background pattern showed up clearly in light mode, which is where you would notice it. The animations behind the hero sticker had real motion design intent. The pricing section, testimonial hover cards, and FAQ accordion all worked. Navigation links scrolled smoothly to their anchors.
The attention to instruction detail is what actually improved here. Every typography rule I wrote in the prompt made it into the output. This is consistent with what Anthropic calls out: the model takes instructions more literally than Opus 4.6, which can mean prompts tuned for the older model need re-tuning. In my case, that literal reading worked in my favor.
App 3: Python CLI File Organizer (with Anthropic SDK) — 5/5
Test three pulled in the Anthropic SDK directly. The brief was a smart bulk file organizer and renumberer — a Python CLI that reads messy filenames, uses Claude to suggest cleaner names, and renames in place.
The tool shipped with two phases built in:
Demo mode — creates 20 messy sample files, runs the preview table, and changes nothing.
Real mode — points at a target folder, analyzes up to 50 files through the Claude API, and suggests renames. You add an
--executeflag to actually apply them.
I pip-installed the requirements, ran demo mode, watched it create sample files, analyze them, and produce an original-vs-suggested name table. Some files were already well-named, so it correctly suggested zero changes. Then I pointed it at a real folder from my machine. Opus 4.7 read each file, returned clean suggested names, and never crashed.
Nothing broke. The SDK integration was correct on the first try. That alone is worth the 5/5.
App 4: DailyDock Mac App (Electron) — 4.5/5
This one was ambitious: a native-looking macOS Electron app that pulls weather, calendar, tasks, email, and news into a single morning briefing window that opens on startup. The idea solves a real problem — most people check five-plus apps every morning before their first coffee.
The prompt was detailed but had no starter code. Opus 4.7 built the whole thing.
The final app looked surprisingly native for a one-shot build. It had a daily quote section, a today's focus input, a to-do list, weather (pending an OpenWeatherMap API key), and a news panel (pending a News API key). I typed a focus goal, added a couple of tasks, and everything saved. The settings panel let me change my name, city, temperature unit, news topics, and toggle auto-open on startup. Light mode looked very close to Anthropic's own Claude desktop app aesthetic.
The half-point deduction: there were some duplicate icons in the header area. Purely cosmetic, easy to fix in a second pass, but it dropped this one to 4.5/5. Given it was a one-prompt Electron build with zero iteration, that is still a strong result.
App 5: Code Duel Game — 5/5
The final build was the fun one — a coding duel game where you compete against an AI bot by solving short code challenges. The interface jumped significantly from what Opus 4.6 produced on the same prompt pattern. Dual types, syntax challenges, difficulty selection (easy, medium, hard), language selection, seed rank, and stats tracking all shipped in one go.
I played a beginner-level JavaScript round and actually beat the AI. The stats panel updated my rank and win count correctly. The "Claude bot" opponent was a nice touch.
This is the one I plan to iterate on further — adding more AI-vs-human mechanics and turning it into something worth publishing.
New Features Worth Knowing
Beyond the raw capability jump, Opus 4.7 ships with several workflow upgrades that changed how I use Claude Code day-to-day.
xhigh Effort Level
The new xhigh setting sits between high and max. Claude Code now defaults to xhigh for all plans, which means deeper reasoning without the full latency hit of max mode. On hard problems, you can still escalate to max. For everyday coding tasks, xhigh is the sweet spot. You can change it on the fly inside Claude Code with the /effort slash command.
The /ultrareview Command
Inside Claude Code, /ultrareview runs a dedicated review session that reads through your changes and flags what a careful senior reviewer would catch — design flaws, logic gaps, subtle bugs. This is different from a syntax lint. I tested it on the job tracker code and it caught two issues I would have missed: a missing null check in the cover letter generator and an inefficient re-render in the dashboard.
Task Budgets (Public Beta)
Task budgets let you set a hard ceiling on token spend for a given run. For long-running agents this is critical — no more runaway reasoning loops burning through credits. Budget controls are in public beta on the API.
3.3x Higher Vision Resolution
Opus 4.7 processes images up to 2,576 pixels on the long edge, roughly 3.75 megapixels. Prior Claude models capped around 1,568 pixels. If you feed it dense UI screenshots, architecture diagrams, or whiteboard photos, the model actually reads the fine detail now. XBOW reported a 98.5% score on their visual acuity benchmark with Opus 4.7, up from 54.5% on Opus 4.6.
Updated Tokenizer
The tokenizer changed in Opus 4.7. The same input text can map to 1.0x–1.35x more tokens than on Opus 4.6, depending on content type. This is worth planning for if you track API spend closely.
File-System Memory
Opus 4.7 uses file-system-based memory more reliably across long, multi-session work. It remembers notes between sessions and uses them to start new tasks with less context upfront. For agentic workflows where the model writes notes to disk and reads them later, this is a meaningful reliability upgrade.
Pricing and Availability
Opus 4.7 costs $5 per million input tokens and $25 per million output tokens — identical to Opus 4.6. The full 1 million token context window is available at standard rates. Auto mode (Claude making autonomous decisions without constant permission prompts) was extended to Max plan users.
The model is live across Claude.ai, Claude Code, the Claude API, Amazon Bedrock, Google Vertex AI, and Microsoft Foundry. For pricing and plan details, check Anthropic's pricing page.
How Opus 4.7 Stacks Up Against GPT-5.4 and Gemini 3.1 Pro
Anthropic published a comparison table in the official launch announcement covering twelve benchmark categories. The pattern is clear:
Coding and agents: Opus 4.7 leads. SWE-bench Pro is the cleanest signal — 64.3% vs 57.7% for GPT-5.4.
Graduate reasoning (GPQA Diamond): tied. Opus 4.7 at 94.2%, GPT-5.4 Pro at 94.4%, Gemini 3.1 Pro at 94.3%. Noise-level differences.
Agentic computer use (OSWorld-Verified): Opus 4.7 leads at 78.0%, GPT-5.4 at 75.0%.
Web research (BrowseComp): GPT-5.4 Pro wins at 89.3% vs 79.3% for Opus 4.7.
Terminal use (Terminal-Bench 2.0): close race, GPT-5.4 self-reports 75.1%, Opus 4.7 at 69.4%.
If you are shipping production coding agents, Opus 4.7 is the pick. If you are running deep web research agents, test GPT-5.4 first.
Final Thoughts
Claude Opus 4.7 is a real upgrade, not a cosmetic point release. Five one-shot app tests landed four perfect scores and one 4.5. Nothing broke. Nothing needed a retry.
The new xhigh default, the /ultrareview command, the 3.3x vision resolution, and the jump on SWE-bench Pro all point at the same thing: a model that handles hard, long-horizon work with more discipline than anything Anthropic has shipped before.
If you build with AI, switch your Claude Code default to claude-opus-4-7 and run one real project through it. The difference shows up inside an hour.
Frequently Asked Questions

Written by
Raman Singh
Raman Singh is a highly skilled marketing professional who serves as the head of marketing at Copyrocket AI. With years of experience in the field, Raman has developed a deep understanding of all asp
View all postsYour AI Marketing Agents
Are Ready to Work
Stop spending hours on copywriting. Let AI craft high-converting ads, emails, blog posts & social media content in seconds.
Start Creating for FreeNo credit card required. 50+ AI tools included.
Related Articles
 General
GeneralNotebookLM For Coders: Turn Docs Into Faster Code
Code work often fails for a simple reason. You do not have the right context at the right time. You read docs in one tab, skim tickets in another tab, and then...
 General
GeneralHow to Optimize for AI Search in 2026: The Complete Guide
AI search has shifted from experimental feature to primary search method for millions of users. ChatGPT Search, Google AI Overviews, Perplexity, Claude, and Gem...
 General
GeneralClaude Opus 4.6 Review: Here's What New!
Claude Opus 4.6 from Anthropic draws attention because teams want an AI model that writes better code, follows instructions, and stays consistent across long se...